


2022年底,OpenAI推出ChatGPT,迅速火遍全球,上线仅两个月注册用户就达到1亿,引发全民关于AI大变革的讨论。
同时,人们对于OpenAI在成立时承诺专利和研究成果全部开放,而现在又不开源代码表示疑虑。OpenAI未来是否会开源代码?开源生态系统在塑造产业链和科技创新方面到底扮演了什么角色?在创新机制上又有哪些可学习借鉴之处?中国是否应该发展自己的AI大模型?发展路径应该如何选择?本文尝试从开源生态系统的视角来观察AI进化的逻辑。
一、开源生态系统的发展历史与国际现状
开源是软件开发中的一种模式,指基于开源许可证的要求开放源代码。这一开发模式允许他人使用、拷贝、修改以及重新发布源代码,在其基础上创新、优化、迭代。
开源文化具有开放、平等、共享、协作、贡献、合规等特点,也是一种先进的大规模的智力协同创新协作模式,并已从软件开发延伸至更多领域。
开源软件从上世纪80年代发展至今,经历了从理想主义模式、服务商业模式,再到如今的多元商业模式等多个阶段(如图)。开源的历史是软件创新自由和版权收益之间不断斗争和平衡的历史,也是处在开源与垄断不断循环之中。服务器操作系统、云计算、大数据、人工智能等新技术都在近几年逐步走向开源。
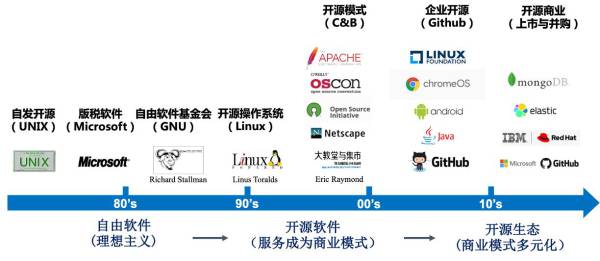
在国际上,开源的重要性已得到广泛认可。开源体系成为西方国家打造数字经济新优势的战略选择。以美国为例,美国对开源生态的建设强调体系化,借助开源帮助政府降低采购成本,开源的发展与研发的突破结合紧密,开源常引导新技术的发展方向。美国政府于2002年开始布局开源生态的建设。从2004年起美国出台了一系列指导政府部门使用开源软件的政策。在2016年和2019年的《人工智能研发战略计划》中均提出,要开发开源软件库和工具包;政府部门不但要支持和使用人工智能开源技术,还要为开源项目贡献算法或软件。
市值超过千亿美元的国际龙头企业也纷纷布局开源。IBM以340亿美元收购了开源软件企业Red Hat,微软以75亿美元收购了GitHub。除此以外,Oracle、Adobe等巨头也纷纷收购开源软件企业,布局开源生态。
二、美国OpenAI诞生ChatGPT的内部运行机制:开源和闭源的博弈、理想主义和商业利益的平衡
2015年底,OpenAI宣告成立。它是以捐赠款成立基金会支持的非营利性实验室,目标是开发“通用人工智能”技术。到2019年时,捐赠款项已无法支撑运营成本,OpenAI成立了一个以盈利为目的的分支机构,并与微软达成投资协议,在股权架构与利润分配上创造了一种与众不同的结构。
(1)微软新一轮投资完成、OpenAI LP首批投资人收回初始投资后,微软有权获得OpenAI LP 75%的利润;
(2)微软收回130亿美元投资、从OpenAI LP获得920亿美元利润后,分享利润的比例从75%降到49%;
(3)OpenAI LP产生的利润达到1500亿美元后,投资方的全部股权转让给OpenAI的非营利基金。
2022年底,ChatGPT成功发布。可以说,微软用上百亿美元的投资“租了OpenAI”。等OpenAI开始赚大钱之后,微软能直接分钱。但如果OpenAI变得极其赚钱,就能拿回微软手中的股份,不再受其制约。
在目前阶段,OpenAI变得不那么开放,为了保护其知识产权和收入来源,开始放弃发布所有研究成果和开源代码的承诺,理想主义让位于商业利益。
三、中国开源生态的现状以及面临的问题和挑战
我国目前已积极在开源领域展开布局,出台了多部政策、法规。很多地方政府也在产业发展规划方案中对开源进行了布局。
开源技术发展、开源基金会的建设等出现在多部“十四五”规划中,包括《“十四五”数字经济发展规划》《“十四五”国家信息化规划》《关于规范金融业开源技术应用与发展的意见》等。多个地方政府,如浙江省、湖北省政府等都在各自的“十四五”数字经济发展规划中将开源技术纳入了发展蓝图。
开源生态能够为我国创新能力体系的建设添砖加瓦。利用与欧美开源模式的差异化发展,我国有机会打造中国特色的开源生态,吸引国际开发者和投资者。但同时中国的开源系统发展也面临多个问题和挑战。
第一,目前,中央和地方在开源建设上的步调还不一致,例如有的地方政府鼓励国际开源社区落地,而忽略了自主建设开源生态的机会。开源体系和对草根创新力量的保护是创新赖以生存的土壤。开源项目可以很好地集中个体的创新能力,保护个体创新的变现权益,可以汇聚全国甚至全球的个体创新者的智慧,对社会面的创新有极大的帮助。我国计算机相关行业工作者数量庞大,目前还没有将草根创新力量聚拢起来。在科技领域,还存在重复建设、重复投资的情况,没有将创新力量体系化。
第二,科技公司的商业竞争阻碍创新开发。为了抢占市场先机,各大科技公司仍主要关注项目的商业利益,对开源的长期价值缺乏认知,企业之间并未建立信任,不利于打造开源环境。同时,即使是在开源项目上,传统的开发方式仍然很普遍,小部分利益相关者起主导作用,不符合开源的利他主义思想和开源生态系统的建设。
第三,对开源机构的行政干预措施仍需优化。目前开源社区、开源基金会等受到较强的行政干预。例如,有的开源基金会目前归部委相关司局管理,但司局的管理范畴和协调力度不足以支撑该基金会向更多的行业和应用场景延伸。同时,部委对基金会采取行政化管理方式,对于需求层层审批,对发展重点并不明确,使得开源机构工作方向不清晰,项目运作效率低下。开源基金会的管理层由部委指派,缺少社会力量的参与,使得开源模式利用民间创新能力的初衷没有得到体现,同时基金会的背景对于与国际科技企业协商合作也受一定影响。
第四,开源机构缺乏核心竞争力。国家级的开源生态倡导机构,例如开源基金会,缺少优质项目以及开发能力等核心竞争力,无法吸引更多企业加入合作。部分大企业在接触开源机构时也因此显得更为抵触,更倾向于保护自身的商业利益。
四、开源生态系统对于塑造产业链和科技创新的意义
开源缘起于奉献和利他的理想主义。开源精神也是一种共享共治的精神,一种打破垄断、开放创新的精神。开源在国际上是作为一种开发模式。软件的开发模式与物理世界的资源开发存在根本的不同,开源的开发环境和理念有机会吸引国际开发者协作共赢,并且在外交和国际合作领域可以产生新的国际影响。
开源体系是重组全球要素资源、优化全球价值分配、改变全球竞争格局的战略选择。具体而言,开源对于创新活力、产业生态、经济发展都具有重大意义。
第一,开源有助于激发创新活力。开源的模式能够汇聚社会中的创新力量,“众筹”草根的创新能力。例如,操作系统领域,全球90%以上服务器操作系统和72%以上移动操作系统均基于开源Linux内核;电动汽车领域,在特斯拉将其代码向全球开发者共享后,全世界范围内迸发出许多电动车企业,促进了电动车行业全球产业链的发展。开源也已成为云计算、大数据、人工智能、区块链、元宇宙等新兴领域的主要开发模式。
第二,开源能够重塑产业生态。开源的项目能够号召和汇聚全社会的力量对其做创新和迭代,从而超越产业中原来的优势者,有机会重新塑造产业生态。例如,在手机的移动操作系统领域,安卓系统凭借开源的优势,快速迭代和扩散,击败了塞班系统,2013年全球装机量就达到80%。
第三,开源能够赋能经济发展。欧盟测算发现,开源软件的投资平均可带来4倍回报,开源贡献者数量每增加10%,年度GDP将提高0.6%。
五、中国开发类ChatGPT大模型的问题和挑战
ChatGPT的问世极大推动了AI时代的发展,将给人类社会生活和生产带来巨变。中国企业在大模型上也展现出极高的开发热情,目前国内至少已经有30多家公司有大模型亮相,其中不乏参数规模甚至超过ChatGPT规模的大模型,涵盖了互联网巨头、AI上市公司、服务器龙头企业、科研院所与一些创业公司。
国内AI大模型呈现出以下几个技术特点:
第一,采用预训练模型提高泛化能力。中国的大模型通常采用预训练模型,使用大量未标注的数据对模型进行训练,从而使得模型具有更好的泛化能力和适应性。目前,BERT是最常用的预训练模型之一,不过也有其他模型如GPT-2、XLNet等。
第二,多任务学习方法,提高不同领域的效果。中国的大模型通常采用多任务学习方法,让一个模型同时处理多个任务。这种方法可以使得模型能够更好地学习不同领域的知识,从而提高模型的效率和准确性。
第三,结合知识图谱,增强理解能力。中国的大模型通常会结合知识图谱进行应用,以增强模型的理解和推理能力。此外,有些模型还会引入实体链接、关系抽取等技术,以更好地理解文本。
第四,建立训练平台,训练规模大。中国的大模型通常需要大规模的训练数据和计算资源才能达到较好的效果。为此,一些企业和机构建立了自己的训练平台和超算中心,以支持大规模训练。
在模型的开源情况上,华为的盘古大模型、复旦大学的MOSS模型、商汤科技的书生2.5模型、鹏程系列的大模型、智谱GLM-130B模型等目前开源,而诸如百度的文心一言、阿里、腾讯、字节跳动等互联网大厂的大模型均未开源或未披露。
目前,中国大模型的发展存在诸多问题,这些问题不但影响大模型的发展,也不利于创新体系建设。
第一,科技企业“千模大战”竞争激烈,商业利益降低开源意愿。各个科技公司只顾“自家门前雪”,关注商业利益,而抗拒加入开源生态。据有的开源基金会的调研,科技巨头中仅有华为对开源大模型展现出兴趣,其他大公司均以商业利益等缘由拒绝透露技术信息。这也导致各个公司存在模型重复开发、重复建设的问题,一家公司取得的突破难以惠及其他公司和开发者。
第二,大模型的开发能源消耗巨大,入场门槛高。大模型的训练依赖于大量的数据计算和超算体系。然而超算耗电量巨大,并且目前中国的超算体系效率比较低。尽管超级计算机的建设方兴未艾,峰值理论算力达到了世界第一,但实际利用率不足。同时,大模型训练所产生的能源消耗也给当地带来较大的环境压力。
六、对开源生态和AI大模型发展的政策建议
第一,国家相关部门对开源生态,以及开源生态对科技创新和塑造全球产业链的战略意义提高认识,做好开源生态的顶层设计,加大力度培育科技创新的土壤。相关部门应认识到开源对于创新的重要性及开源开发模式所带来的社会生产模式的改变。除了更好地发挥举国体制集中力量办大事以外,开源也是建设科技创新土壤的重点,需要将开源生态的发展提到战略高度,中央和地方统一步调,致力于打造中国的开源生态,提出行业标准,保护和汇聚社会创新草根力量,争取培育出中国版的OpenAI。
第二,在人工智能模型的开发上,鼓励科技公司加入开源生态,集合开源的力量,助力中国的类ChatGPT大模型的发展。人工智能大模型不仅仅是人类的工具和助手,更是人工智能时代新的操作系统,是人工智能的底层架构和基础设施。中国必须发展出自己的大模型,要充分认识其重要意义。同时,要客观、真实地分析影响企业开源的因素,在开源前,鼓励各企业之间建立定期沟通交流机制,将开发技术的信息脱敏后充分交流,并且探讨如何建立开源后的协同运营管理机制。对于大模型的开发,还应当进行多维度的思考。借助开源社区和社会创新力量,积极探索其他的人工智能发展道路。大模型是否是通用人工智能发展的唯一正确的路径,是否有更低能耗、更高效率的技术途径,仍需要进一步探索。例如,可以考虑从生物神经网络的认知逻辑结构入手,寻找更好的通用模型。
第三,积极培养开源人才,建设开源文化。推动开源社区、开源基金会等机构与高校、科技企业、研究院等机构合作研究;举办全球性质的开源大赛,选拔优秀人才,展示创新成果,传播普及开源理念,对青少年开展开源文化的教育,为推进开源生态繁荣和可持续发展提供动力和支撑。
第四,鼓励地方政府为开源社区、开源机构提供落地支持。地方政府为开源机构提供包括办公地点、资金支持、算力支持、知识产权优惠政策、人才政策等支持,助力开源机构提高自身核心竞争力,与开源机构互助互利,合力建设中国特色的开源生态系统,为科技创新和科技自立自强注入强大动能。
(作者单位:清华大学人工智能国际治理研究院)













