


摘 要:随机对照试验被广泛视为社会工作干预的黄金法则。但是,由于在干预对象数量、实施规范、质量评价工具等方面的条件制约,以及社会工作的伦理要求,现实情境中的社会工作干预往往难以实现严格的随机对照试验。基于一个针对儿童积极行为发展的“让我们做朋友—河北”干预项目实施全过程的分析显示,在随机对照试验受到限制的情况下,可以在干预方案设计、干预实施和干预效果评价等不同环节选择非随机干预次优策略,这些次优策略也展现出了比较明显的干预效果。此外,在社会工作服务领域,统计学意义与临床意义应共同成为衡量干预效果的核心标准。
关键词:随机对照试验;社会工作干预;儿童积极行为发展;“让我们做朋友”
作者吴帆,南开大学社会工作与社会政策系教授;晏浩,香港中文大学—南开大学社会政策联合研究中心助理研究员。(天津 300350)

一、问题的提出:社会工作干预实现随机对照试验的条件制约
随机对照试验(Randomized Controlled Trial, RCT)是将符合要求的研究对象随机分配到试验组和对照组,在一致的条件或环境下接受相应的试验措施,用客观的效应指标对试验结果进行测量和评价的一种试验设计。随机对照试验能确保目标人群中的每个个体都有同等机会被选为试验对象,且保证每个试验对象也都有同等机会被分配到试验组和对照组,由此,各种已知和未知的干扰因素能够在基线时被均衡分布到试验组和对照组中,使两组在可能产生混杂效应的非试验因素方面保持良好的一致性和平衡性,可以减小选择性偏误(selection bias)、实施过程偏误(performance bias)、退出偏误(attrition bias)和测量偏误(detection bias)等系统偏误,有助于研究者分析仅由于试验因素造成的不同组之间结果差异的大小,进而推导出干预策略和效果之间的因果关系。高质量的随机对照试验处于循证研究证据等级的金字塔顶端,也被广泛视为社会工作干预(social work intervention)的黄金法则。而非随机干预研究(Non-Randomized Studies of Interventions,NRSI)则不使用随机化方式将干预对象分配到不同研究组别中来评估干预有效性, 处于证据金字塔下端的队列研究、病例—对照研究、自身前后对照研究、横断面研究、时间序列研究,以及设计不当的“准随机对照试验”等都属于NRSI的范畴。
在社会工作干预中,Meta分析、随机对照试验和系列非随机干预被统称为证据为本的实践(Evidence-Based Practice,EBP)。EBP的最佳证据并非只指向Meta分析和随机对照试验,社会工作干预方法的选择应该建立在所需回答的问题及可获得的最佳证据基础之上。如有研究通过为期3个月的集群随机对照试验,评估了社会接触和教育干预在改善社会工作学生对精神疾病态度方面的有效性;也有学者则出于实践和伦理的限制,在难以使用随机化程序和对照组的情况下,审视和分析了时间序列设计在形成性项目评估中的应用和效果。
实际上,在社会科学领域,由于各种客观条件的制约,无法实现随机对照试验是普遍且正常的。因此,尽管随机对照试验的成果数量庞大,在现实情境中却难以找到可靠的、可供借鉴的试验案例。随机对照试验一般可分为解释型(eRCT)和实用型(pRCT)两类。前者旨在探讨标准条件下干预的功效,占所有随机对照试验的99%;后者讨论在真实环境下干预的实效,由于实施难度非常大,占比仅为1%。一项研究显示,1995年1月至2005年5月公开发表的1452篇标题有“随机对照试验”的pRCT文章中,仅有0.62%的文章采用的方法能基本达到随机对照试验的标准。由于社会工作干预往往在真实情境中展开,想要实现随机对照试验,不仅面临着来自样本量、抽样方式和质量评价等方面的限制,也面临来自社会工作伦理的挑战。
首先,随机对照试验一般需要较大样本量。大样本研究的效果估计相对于小样本研究更加精确,而目前的统计技术通常也只对大样本提供正确的估计,对小样本则会产生未知或不理想的结果,然而,社会工作领域的小样本干预非常普遍,有限的样本量对干预的统计功效(statistical power)和统计显著差异(statistical significance)等提出了挑战。其次,随机对照试验以随机抽样和分组对照为基础规范,而社会工作干预通常难以达到这些基本要求。一方面,社会工作的服务对象有很强的指向性甚至经常是固定的,一般无法实现抽样误差最小的多阶段分层抽样。而且,在一个干预点难以限制不同组别干预对象之间的交流,干预效应溢出(spillover)明显,导致对照组的作用受到制约。另一方面,随机分组的操作过程往往与社会工作伦理原则存在一定的冲突。虽然随机分配有助于将干预方法对干预团队、受试对象和评估者设盲以减少偏误,但往往难以与干预对象的“知情同意”或“有权接受服务”的权利平衡。最后,随机对照试验的质量评价工具要求保证试验的透明化、科学性和完整性。目前可用于评价随机对照试验质量的工具非常丰富,这些工具要求在随机对照试验中,对试验的设计、实施、测量、随访、结果做出全面且准确的记录和描述,并对每一项记录和描述说明判断理由,缺失其中任何一项,随机对照试验的结果就倾向于夸大干预效果。由此,从试验设计到结果评估的每个环节都需要投入大量的人力、物力、财力和时间,成本高昂,同时也需要大批受过严格培训的专业督导跟进干预全过程,而目前社会工作干预的实施过程很难达到上述要求。此外,研究对象之间异质性大、干预时间较短、替代指标使用较多也会造成社会工作干预实现随机对照试验的可能性受到限制。
因此,在现实情境中的社会工作干预难以实现随机对照试验时,研究者和实践者通常会根据实际情况制定补充性、递补性或替代性的NRSI次优方案。具体而言,补充性的NRSI提供干预措施在不同人群中是否有效、组别之间是否发生相互作用、非试验环境中是否存在基线偏倚等背景信息;递补性的NRSI提供项目或假设的额外信息,如为参加短期RCT的被试提供长期结果;替代性的NRSI提供比RCT确信度更高的证据。在次优方案的选择中,确定NRSI的具体范围是基础且关键的,然而,不同NRSI在偏倚风险评价、证据确信度评级上的侧重点有所不同,因此目前没有一个普适性的标准能够明确指出应当使用何种NRSI, 而文献检索、预调查以及专家咨询在一定程度上能提高研究者后续判断的准确性。本研究试图探索和回答在随机对照试验受限的情况下,如何设计一个社会工作干预项目并确保效果。研究基于一个针对儿童积极社会行为发展的“让我们做朋友—河北”干预项目实施的全过程,旨在探讨在无法实现随机对照试验的条件下,如何在干预设计、干预实施和干预效果等不同环节进行NRSI次优方案的选择,以及如何从统计学意义和临床意义理解和探讨社会工作干预的效果。
二、次优方案的选择策略:基于“让我们做朋友—河北”的分析
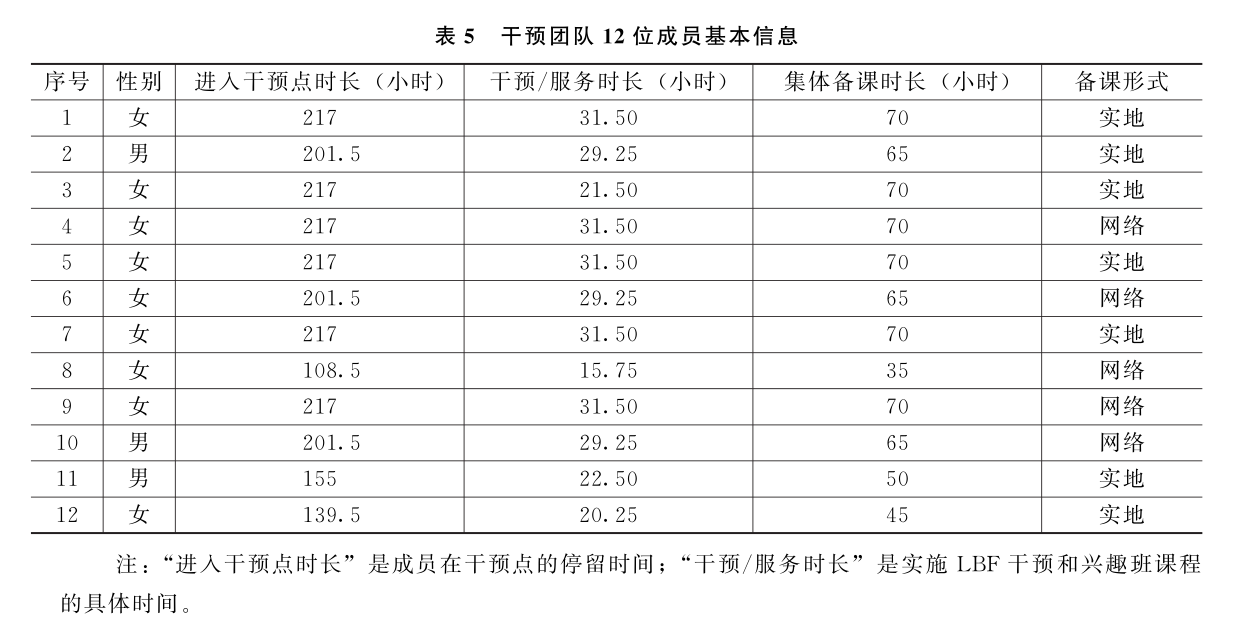
“让我们做朋友”(Let’s Be Friends,LBF)源自美国“做出选择”(Making Choices,MC)干预项目并经过了中国本土化,是一项基于社会信息加工理论(social information processing theory)对儿童情绪管理和积极社会行为技能展开训练的社会工作干预,能够有效减少儿童攻击性行为并提升儿童社会交往技能。这一项目于2011年9月至2019年7月在天津、西安、河北等地陆续实施,一系列统计检验和质性资料分析证明这一干预在中国情境下显示出稳定和持续的效果,本研究主要针对“让我们做朋友—河北”干预项目展开分析。这一干预于2019年5月至7月在河北省保定市博野县的北彦小学实施,属于一个定向的扶贫项目。博野县当时是保定市的省级贫困县,地理位置较为封闭,资源相对缺乏,当地政府和校方对扶智类扶贫项目有高度的热情。北彦小学共有11个班级,1—5年级均开设2个班级,6年级开设1个班级,全体在校学生263人构成了这一项目的全部服务对象。干预团队由作为项目督导的3位社会工作专业的高校教师,以及作为干预成员的12名社会工作专业的研究生和高年级本科生组成。由于干预对象具有较强的指向性,干预过程中多种因素限制了随机对照试验的实现,但是干预结果表明即使无法完全实现随机对照试验,次优方案仍识别出了比较明显的干预效果。
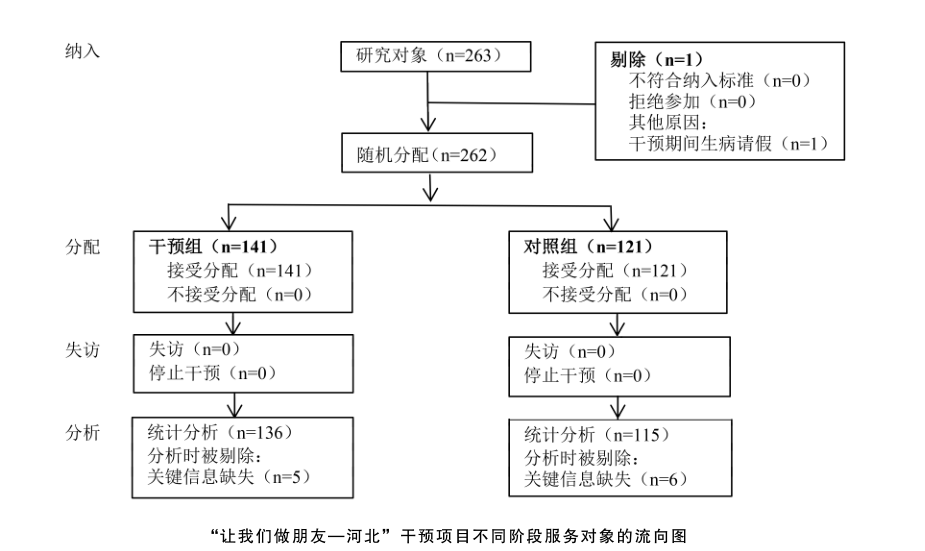
下图呈现了从干预设计到评估不同阶段服务对象的流向。在干预具体实施期间,1名学生因病未能参与干预项目,予以剔除,最终262人进入随机分配,其中141人进入干预组,121人进入对照组。所有学生均接受分配,且干预全程没有失访。在统计分析阶段,由于小学生的理解能力有限或对家庭情况了解不足,干预组和对照组分别有5名和6名学生填答的量表缺失了关键信息,予以列表删除(listwise deletion)。即删除关键信息缺失的11个样本。这一操作过程一般不会对干预效果的分析产生影响,原因主要有三个:其一,部分儿童存在问卷填答困难以致信息缺失的情况属于完全随机丢失(missing completely at random, MCAR),即信息缺失的概率与信息本身及其他变量值完全无关,因此删除含有缺失值的数据,不会影响样本的无偏性;其二,列表删除是诸多统计软件包处理缺失数据的默认方法,被证明在数据缺失率较高时带来的偏误小于各类插补法;其三,干预团队在组织服务对象填答问卷时,对每个问题均进行了详细讲解,并全程解答疑问直至填答结束,同时尽可能联系家长确认相关信息,因此缺失关键信息的样本占比很小,对结果测量的影响不大。
(一)干预设计:确定和抽取干预对象
在干预设计方面,主要涉及确认样本量大小、服务对象同质性和抽样方法这三个具体环节。
其一,样本量估计是随机对照试验的关键步骤,旨在保证一定精准度的前提下确定最少观察单位数。样本量大小通常取决于期望的统计功效、显著性水平和效应量(effect size)。统计功效是指在假设检验中,拒绝原假设后,接受正确的替换假设的概率。学界普遍认可0.8及以上的统计功效水平,即当统计功效达到0.8时,能有80%的可能性保证总体中存在的现象可以通过样本检验得到识别。效应量表示不同处理策略下的总体平均数之间差异的大小,能为各列观测数据的关系程度提供稳定可靠的考察。本研究采用Cohen的d值,效应量小、中、大的判定标准分别为0.2、0.5、0.8。在“让我们做朋友—河北”干预开展前,我们首先运用G*power 3.1确定样本量。结果表明在保证效应量为0.20、统计显著性为0.05的前提下,统计功效为0.80时,需要394名干预学生和394名对照学生,统计功效降至0.75时,需要348名干预学生和348名对照学生。然而,干预点的学生总数只有263人,我们进一步将效应量设置为0.35,统计功效保持在0.75,统计显著性仍为0.05时,所需的干预组和对照组的数量均为115,基本满足干预的样本量要求。因此,在样本量受限的条件下,接受效应量、统计功效和显著水平的部分损失是常见的应对方式。
其二,随机对照试验严格限制纳入标准,要求尽可能纳入同质人群,并减少有影响的变量。“让我们做朋友—河北”项目的干预对象固定,没有变动空间,然而通过收集干预对象的异质性特征,提取协变量,在后续统计分析中控制协变量,能够减轻未严格限制纳入标准带来的结果偏差。为了解服务对象内部的异质性状况,干预团队统一组织并指导干预对象集中填答问卷。根据服务对象的流向情况,最终获取有效问卷251份,回收率为95.80%。数据显示,干预对象在人口学特征、在校学习状况、家庭背景、居住安排等大部分变量上的同质性较强,但也存在一定的异质性。其中,男孩占比50.6%,平均年龄9.69岁,干预对象的兄弟姐妹数平均为1.1个,18.3%是独生子女,有1个、2个、3个及以上兄弟姐妹的比例分别为67.7%、9.6%和4.4%。父母的受教育程度大多为初中;55.2%的父亲和16.3%的母亲在外地工作,父亲外出打工、母亲留守家庭陪伴儿童的生活及居住安排更为普遍。绝大部分儿童(77.3%)认为自己与父母关系良好,而认为与父母关系一般、不太好、很差的比例分别为10.9%、12.6%和3.2%;从学生期待的受教育程度看,76.2%的学生希望接受大专及以上学历的教育,有5.2%的学生只想上到初中。总体上,虽然干预对象相对固定,但内部较强的同质性有效缓解了因纳入标准不严格造成的结果偏差。
其三,随机抽样是随机对照试验发挥黄金法则作用的根基。随机抽样包括多种方法,按抽样误差从小到大依次可分为分层抽样、系统抽样、简单随机抽样和整群抽样。“让我们做朋友—河北”的服务对象具有较强的指向性,无法实现在省、城市和学校等不同层面的分层抽样。出于便捷性和社会工作伦理方面的考虑,干预团队最终确定了以班级为抽样框进行整群抽样的替代方案:抽样方案调整为针对1—5年级学生,项目督导(不了解干预对象的具体分班情况,不参与后续的具体干预过程)通过抽签的方式,从每个年级的两个班级中随机抽取一个班级,被抽取班级的全部学生(108名)进入干预组,未被抽取班级的全部学生(121名)进入对照组。6年级的1个班级(33名)整体进入干预组。
(二)干预实施:环境差异性和干预效应溢出的控制
随机对照试验要求在干预实施过程中,确保干预组和对照组所处的内外部环境一致,保证对照组与试验因素完全隔绝,以减小实施过程偏误。但因社会工作伦理等因素的影响,无法实现内外部环境的一致性,可通过强化对照意识来减小干预效应溢出。
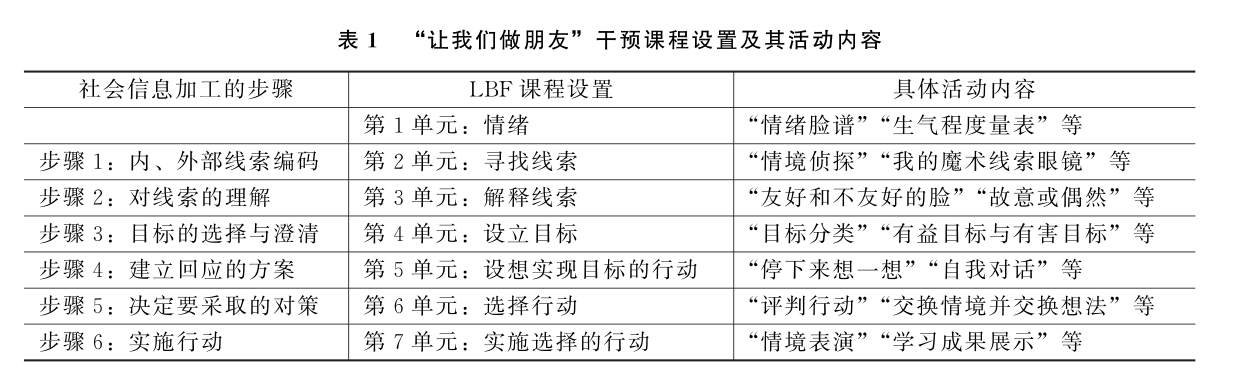
第一,“让我们做朋友”干预突破伦理困境,针对“对照组”开展了兴趣类课程。随机对照试验要求将研究对象随机分配到干预组和对照组,除试验因素外,对照组所处的内外部环境需要与干预组保持一致,即两组所处环境中存在的混杂因素应是一致的。Sander Greenland, “Randomization, Statistics, and Causal Inference,” pp.421-429.其中,内部环境表现为各组的规模、性别构成、年龄分层等,外部环境表现为干预人员的行为、各组在干预期间的生活场所等。但在真实情境中,干预对象的随机分组与社会工作伦理要求之间存在一定的冲突。“让我们做朋友”干预旨在帮助儿童实现信息加工能力的提升,进入干预组则意味着增大了儿童社会交往能力提升的可能性,至少不会变差。而社会工作伦理要求所有参与者都应该受到公平对待,参与者均“有权接受服务”。为了兼顾主观偏误和服务对象的权利,团队针对干预组开展了7周“让我们做朋友”的干预课程(表1), 每周2次,每次90分钟,称为“LBF组”。LBF组的课程旨在提升儿童情绪管理能力和社会信息辨析能力,增强儿童在社会交往中的理性认知和合理行为,促进儿童积极的社会交往;针对对照组开展了7周兴趣类课程,每周1次,每次90分钟,称为“兴趣班”。根据前期对北彦小学的需求调查,兴趣班开设了音乐课、绘画课、英语课、趣味科学和利奇游戏5类课程。兴趣班旨在通过多样化的兴趣课程,培养服务对象的兴趣爱好和实践能力。虽然以兴趣班为对照组会增加实施过程偏误的概率,但这种做法更加符合社会工作“以服务对象需求为基本导向”的伦理原则,对参与干预的学校和学生的意义更为深远。
第二,通过强化对照意识降低干预效应溢出。随机对照试验设置对照组的目的在于将对照组与试验因素完全隔绝,能够有效区分干预带来的结果与其他非干预因素带来的结果。但是,“让我们做朋友—河北”干预实施过程中难以避免效应溢出问题。为了尽量降低干预效应溢出,干预团队从以下方面进行了准备:其一,干预实施前,由3位督导老师对干预团队开展了30个小时的系统性培训,重点掌握干预研究的原则、干预理论与实践框架,以及干预课程内容及实施全过程。同时,培训阶段不断强化干预团队的对照意识。其二,干预实施前,实施集体备课,并注意掌握兴趣班课程设计时尽可能避免“让我们做朋友”的干预要素。其三,干预过程中,每次干预课程均配置3位成员,1位负责主讲干预课程,另外2位提供辅助(如带领小组讨论)并保持记录,彼此监督并强化对照意识。其四,由专业教师担任督导巡视和观察每一次干预课程,及时提供支持。其五,在对干预组学生讲授课程时,通过“我和拉尔夫有个约定”的故事以期达成激励学生对课程内容保密的目标。上述做法尽可能减少了干预效应溢出对对照组作用的削弱。
(三)判断干预效果:多重结果共证、多中心研究和历史对照
随机对照试验要求在评估干预结果时同时报告内部有效性和外部有效性。内部有效性指试验中系统偏误减少的程度,内部无效主要来自选择性偏误、实施过程偏误、退出偏误和测量偏误。外部有效性指研究结果应用于研究对象以外的其他人群的可能性。外部无效受研究对象的特征、干预措施的实施方法和结果的评价标准等因素的影响。本研究主要通过多重结果共证、多中心研究(multi-center study)和历史对照(historical control)的方法进行效果评估,在一定程度上可以弥补有效性的损失。多重结果指标的对比能相互印证,得出综合结论。因此大多数随机对照试验会同时使用多重结果指标,如定性资料和定量数据相结合,临床效果和统计学效果的共证。由此,在收集数据时过多使用替代指标所带来的测量偏误也能够被部分消减,从而提高整个试验结果的内部有效性。
在随机对照试验的结果测量中,应该使用学界已有并得到公认的指南或量表,这样既能够提高测量质量,也能够与其他同类试验的结果进行多中心研究和历史对照。多中心研究是由多个研究者按照同一干预方案在不同干预点同时进行的临床试验,每个干预点必须严格遵循干预方案,以保证数据的一致性和可比性。历史对照指与自身先前的干预经验(内对照)或与其他同类型干预的成果(外对照)相对比,从而得出结论的非随机、非同时的研究。有效的多中心研究和历史对照能弥补干预时间过短等因素带来的结果偏误。如前所述,“让我们做朋友”源自美国“做出选择”干预项目,一系列实证研究显示“做出选择”基于不同时间不同学校,对美国儿童的干预效果保持了较强的稳定性和持续性。“让我们做朋友”在天津、陕西等地开展的结果也证明了该干预项目增强了中国儿童的社会信息加工能力。尽管“让我们做朋友—河北”项目的干预时间较短,但同样的干预方案在不同干预点的开展提供了可信的多中心比较和历史对照,增强了干预结果的真实性和对外适用性。
三、干预实践效果的统计学意义和临床意义
基于干预设计、实施和效果评价的随机对照试验的次优方案设计,“让我们做朋友—河北”干预团队顺利完成了为期2个月(干预活动时间14天)的干预实践。我们分别从统计学意义和临床意义两个角度,来探讨这一干预实践的效果。统计学意义是指干预组和对照组之间的差异是真实可信的,而非抽样误差或其他干扰因素所导致,被广泛应用于推断随机对照试验的效果。临床意义是指对服务对象进行干预后,服务对象的某项指标发生实际的、正向的变化,并能为之后的干预提供数据支持和决策依据。基于外部标准的报告,以及被试对象对干预的满意度、自我感觉的改善程度是临床意义重要的检验标准之一。统计学意义对应于“统计结论”,临床意义对应于“专业结论”,在干预实践中,两者共同服务于结果指标,因此只有将统计结论与专业结论有机结合起来,才能够得出恰当的与客观实际相符的正确结论,即“最终结论”。因此,我们认为社会工作干预最为理想的实践效果是兼具统计学意义和临床意义。在随机对照试验操作规范时,这种理想结果极为容易实现。如果统计结论与专业结论不一致,则最终结论需要根据“实际专业情况”考虑:统计结论有意义而专业结论无意义,则可能由于样本含量太大或研究设计存在问题,那么最终结论应该为没有意义;相反,统计结论无意义而专业结论有意义,则可能是样本含量不够大或设计不合理,最终结论应被认定为有意义。
我们采用平行混合研究策略(mixed-methods research)对“让我们做朋友—河北”干预实践效果展开分析。平行混合研究策略是在研究中整合定量和质性,将二者的研究视角、数据收集、分析和推断技术结合起来的方法,这一方法与统计学意义和临床意义之间的关系相互契合:基于量化方法获取的统计学意义和基于质性方法获取的临床意义本质上是三角互证关系,研究者通过寻求二者之间的趋同性、确证性和对应性,最终确定研究结论。研究策略的具体逻辑如下。
其一,基于量化方法评估干预效果的统计学意义。研究运用专门针对“让我们做朋友”项目开发的能力层级量表(skill level activity, SLA),用以测量儿童如何对日常的社会交往情境做出解释和行为反应,并以此进行系列检验和模型构建。SLA量表由“躲避球”“数学课”“新裤子”“午餐”和“新杂志”5个故事与线索编码(特定情景中发现的线索数量)、线索解释(是否表现出敌对归因)、目标设立(选择的目标是有益的还是有害的)和决策回应(采取何种行为反应)4个维度构成。5个故事与4个维度一一对应,共设有20个题项,用于对干预组和对照组的前后测,量表的得分越高代表社会信息加工能力越强。
其二,运用三个具体方法来评估干预效果的临床意义。第一,计算最小临床重要性差值(Minimum Clinically Important Difference ,MCID)。MCID是指被干预者认可的最小得分变化值,主要回答“量表得分改变多少才被认为是干预有效”的问题,是评估临床意义的重要工具,旨在克服统计学意义的缺陷。第二,访谈干预团队12位成员,基于访谈资料,了解他们的观察和感受,深入分析干预给服务对象带来的影响和改变。第三,记录典型个案,全程跟进和呈现干预对象的变化,进一步增加干预效果的评价维度。
(一)干预效果的统计学意义
运用SLA量表对干预组和对照组展开前后测并进行数据整理后,对各变量进行平衡性检查以提取协变量,依次进行配对样本T检验和独立样本T检验,并运用有序logistic回归模型,来探讨干预在统计学意义上的成效。所有统计分析基于SPSS22.0开展。
首先,为进一步消除不可预见和无法观察到的因素影响,减小选择性偏误,研究采用双变量检验对协变量进行平衡性检查。针对连续变量使用T检验,针对分类变量使用卡方检验。在性别、年龄、年级、兄弟姐妹数量、是否为独生子女、父亲与母亲的受教育程度、父亲与母亲的工作地点、与父母的关系,以及期望的教育程度这11个变量中,8个变量的p值大于0.05,说明大部分变量在干预组(LBF组)和对照组(兴趣班)之间达到了平衡。但是在“年级”(P=0.001)、“母亲受教育程度”(P=0.000)和“父亲工作地点”(P=0.002)变量上则不平衡,在后续的统计分析中会将其纳入协变量进行控制。
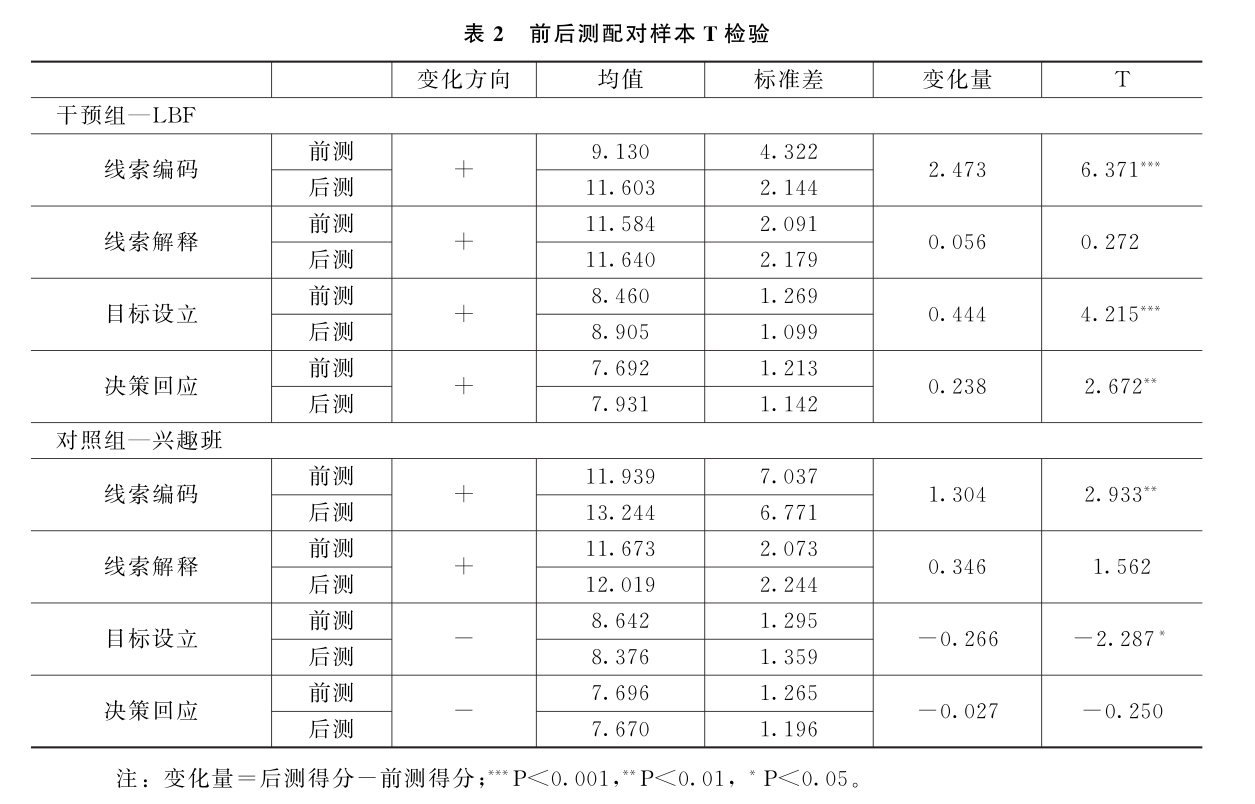
其次,为检验组内有效性,研究分别对干预组和对照组前后测得分的差异进行配对样本T检验。表2(具体题项的详细结果省略)显示,对于干预组,线索编码维度、线索解释维度、目标设立维度、决策回应维度的后测得分均高于前测得分(仅线索解释维度统计不显著),总体呈现出积极的变化(变化方向为+),直接表明了干预的有效性。而作为对照组的兴趣班,存在后测得分显著高于前测得分、后测得分显著低于前测得分、不显著等多种情况,即积极、不变甚至消极的变化都存在。对照组在社会信息加工能力不同维度毫无规律的变化也间接支持了干预的有效性。整体而言,干预组在线索编码、目标设立和决策回应三个维度上的得分变化都显示出比对照组更为明确的积极变化。
再次,为进一步阐明干预对儿童社会信息加工能力的提升程度,研究采用独立样本T检验对干预组和对照组前后测得分差值的差异进行检验。表3的数据结果表明,在11个题项上,作为LBF的干预组前后测得分的差值均高于作为兴趣班的对照组,表明干预组的社会信息加工能力得到了更为明显的提升,具体反映在线索编码维度的4个题项,线索解释维度的2个题项,目标设立维度的5个题项,以及决策回应维度的4个题项上。但是这些差异并不都具有统计学意义(仅在目标设立上P<0.001),因此,需要通过回归模型来进一步辨析这些差异是否能够归因为干预策略。
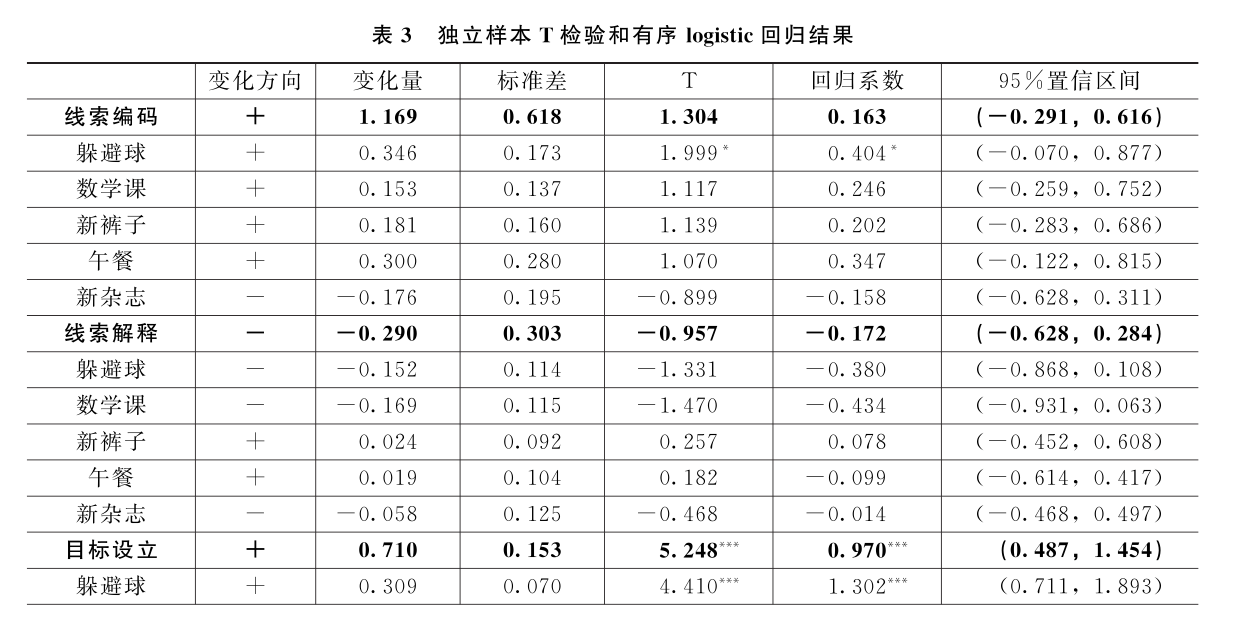
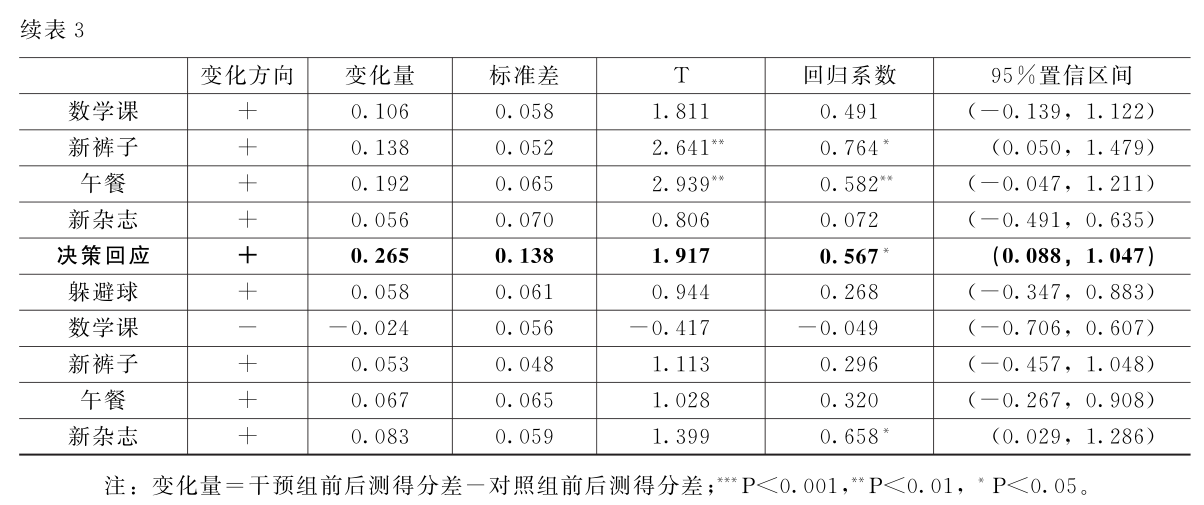
最后,采取有序logistic回归检验干预的整体效果。模型以是否接受LBF干预为解释变量,以对照组产生哑变量作为参考,同时对“年级”“母亲受教育程度”和“父亲工作地点”三个协变量进行了控制。回归系数表示效应量,即两组间前后测得分差的差异。结果(表3)显示,干预组与对照组的分值差在“线索编码”“目标设立”和“决策回应”三个维度上具有显著差异,这说明“让我们做朋友—河北”对干预组学生的社会信息加工能力具有明显的干预效果。
(二)干预效果的临床意义
在随机对照试验中,只有在明确结果指标变化的临床意义后,才能为后续研究提供充分的证据,也才能为优化干预方案提供支撑和依据。而且,相较于干预是否在统计学上显著,临床意义更加关注干预效果大小。因此,临床意义也应成为衡量一个社会工作干预是否有效的重要标准。由于MCID并不要求进行显著性检验,即不要求计算P值,能够在一定程度上克服统计学意义的缺陷。通常使用的MCID值计算方法有效标法、分布法、多元线性回归模型法等。“让我们做朋友—河北”项目采用分布法中的标准测量误差(SEM)法,计算公式为:
MCID=XⅹSEMbaseline
其中X的取值范围:X=1(小效应),X=1.96(中效应),X=2.77(大效应)。
SEM法通常将X取值为1.96,薛红红等:《基于量表得分的最小临床重要性差值(MCID)制定方法》,《中国卫生统计》2019年第3期。如果变化量的数值大于MCID,表示干预带来的改变有效,即具有临床意义。表4的数据表明,线索编码的所有题项、目标设立的大部分题项以及线索解释和决策回应的部分题项均具有临床意义。整体上,“让我们做朋友”干预的临床意义明显,并能够与统计学意义相互印证。
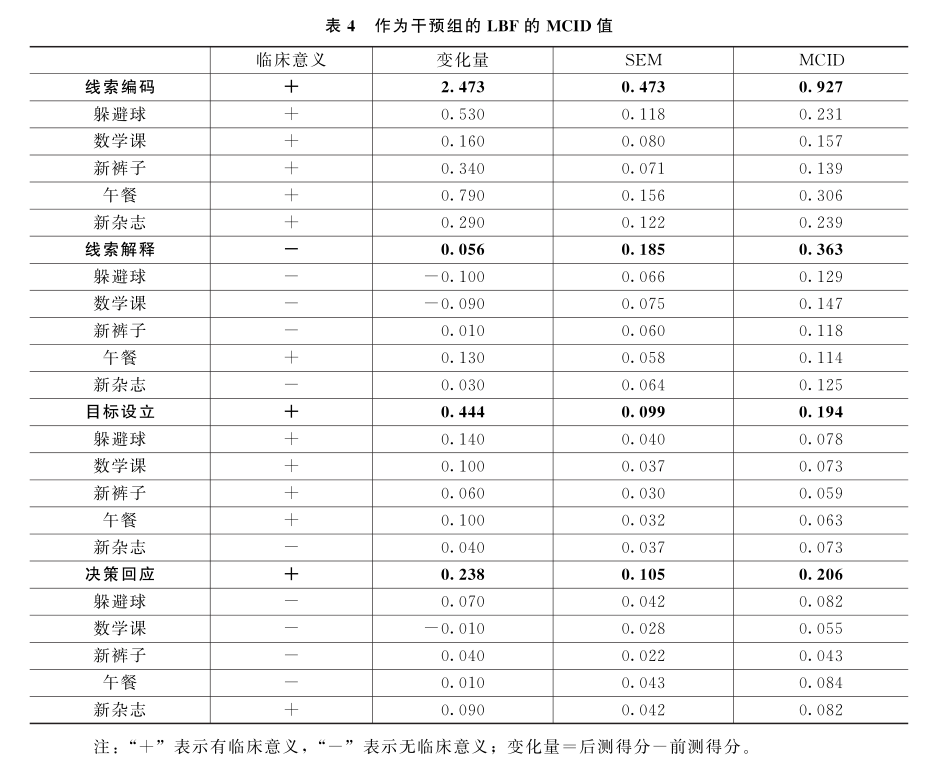
同时,现场观察则可以掌握干预对象对干预活动的直接反应和真实变化。我们对干预团队的12位成员展开了访谈,成员基本信息见表5。
根据访谈资料,在干预初期,学生们在社会交往方面表现出不同的问题。一些女孩表现出较低的表达意愿,与老师的互动频率较低。“女孩们更内向,不敢说话;男孩们比较活跃,试图引起老师注意”(成员10)。低年级的一些学生表达能力相对较弱,“低年级的小朋友,说话声音很小,语言组织也不太通顺”(成员4)。性别隔离因素对同辈交往形成了明显的影响。“高年级同学分组的时候会偷偷换道具,就是为了不和异性坐在一组”(成员9),“排队的时候,男生和女生会自动分成两列,不会交叉着排队”(成员3)。高年级不同性别的学生各自形成阵营,导致部分学生在一定程度上被边缘化,并出现扮演“阵营领袖人物”的中心化个体,性别对立成为鲜明特点。整体上,学生普遍缺乏规则意识,尽管共同商议制定了干预课程的“活动契约”,仍然经常出现无视规则、违反契约的情况。部分学生表现出较强的攻击性,“我们的第一节课需要大家一起讨论制定规则,讨论中,一个孩子突然把椅子推倒在另一个孩子身上,于是讨论紧急终止了”(成员8),“争抢东西的情况挺严重的,分组用的小道具,有的同学直接抢别人的”(成员1)。
在干预过程中,为了更好地应对和改善学生们的互动问题,干预团队针对LBF组采取了一些措施。首先,充分鼓励学生之间的交流与互动,“我们课堂的互动形式是很多样的,尽量让同学们发出不同的声音,说出自己想说的话”(成员4)。同时基于干预内容,采取有效的措施提升学生的表达能力。“有一类‘虚假积极’的小朋友,他们习惯于积极举手,但实则‘完全没想好’或者内心根本不想发言以至于说不出话,我们会将这些小朋友分在每组潜在的小组领导者身边,使他们能够在全员认真参与的环境中逐渐学会学习与表达,增加有效的知识输入与输出”(成员12)。其次,团队成员有意识地引导学生形成正确的性别观念,“我们试着告诉这群单纯可爱的孩子们,试着丢掉之前的‘包袱’,去更好地了解对方,把握好相处的界限,相信不同的性别不会阻碍我们成为朋友”(成员9)。再次,通过平衡课堂的趣味性和秩序性等措施缓解学生之间的人际冲突问题,“为了培养小朋友们的自主性,我们开始在小组当中选举组长,这样一来,组长的责任感被激发出来从而更加积极了,也使得小组更有纪律性和组织性”(成员7)。
在干预后期,干预组的学生在沟通表达和人际交往方面有较大的变化。学生的表达意愿明显增强,胆怯情绪有所改善,积极参与课堂互动和交流讨论,“尤其是之前不太活跃的同学,改观很大,变得更主动了”(成员6)。年级区隔和性别隔阂程度也减轻了,“只要不是拉手的亲密动作,大家都能接受了”(成员10)。此外,同学们的情绪管理能力提升,攻击性行为和人际冲突缓解,“我们班上有4个男生,最开始的时候完全不能坐在一起……哪句话不对了就容易起冲突。最后几节课,我们有意识地让他们组成一组,表现得很好……最初的矛盾状态基本化解了”(成员2)。
干预团队持续跟进和记录了一些在社会信息加工能力方面存在明显问题的个案,观察并在每次干预课程后记录个案产生的变化。其中一位四年级男生H参与干预全过程的变化引人注目。H目前与爷爷奶奶、母亲,以及弟弟和妹妹同住,父亲常年在北京打工,全年与父亲一起居住的时间大致为3个月,而母亲患有轻度的精神疾病。父母的文化程度均是高中(中专)。H自评和父母关系很好,家庭经济条件和大多数同学差不多。H个人有接受教育到大学本科的强烈意愿,最理想的职业是军人。他的兴趣爱好比较广泛,包括体育活动、书法、看书和手工等。在干预初期,H存在比较明显的社交问题。由于说话口齿不够清楚,加之有时不注意卫生,长期处于被同学排斥的状态,也缺乏主动与同学交往的意愿。在干预过程中,干预团队一方面针对H的实际情况,强化对H“让我们做朋友”的技能训练,干预课堂上积极倾听,鼓励并引导H的表达,并予以共情与有效支持;另一方面通过干预课程提升其他学生的社会信息加工能力,为H创造出一个友好的同辈群体环境,使他有意愿展现出积极、健康的行为取向。在干预后期,H成功地与两位同学成了朋友,对于近期是否“被同学嘲笑”“被同学孤立”“遇到和同学关系不好的情形”“和同学吵架”等问题,H均回应没有再发生。而且干预团队成员对H的观察和个案记录,显示他在表达能力、交朋友意愿与同学和老师交流互动等方面都有了明显改善。
总体而言,在“让我们做朋友”干预对研究对象社会信息加工能力的提升方面,统计学结论显示干预在大多数维度上有显著意义,临床结论则显示干预在全部维度上发挥了作用。如前所述,统计学意义和临床意义并不是相互替代的关系,而是结合起来共同服务于对干预效果的判断。对统计学不显著而临床有意义的部分,存在样本量不足够大从而影响P值检测的可能性,临床结果仍然具有参考价值。
结论与讨论
随机对照试验为社会工作干预的科学性和可信度提供了一个理想的实践框架,在有条件的情况下理应成为社会工作干预的黄金标准。但是,由于各种客观与主观因素的限制,社会工作实务领域真正能够遵循随机对照试验标准,并通过质量检验的干预非常少见,此时纳入非随机干预研究的设计进行综合考量,使得来自NRSI的证据同时作为得出结论的支撑,是一种必要、合理的选择。本研究根据“让我们做朋友—河北”干预全过程,从样本量、抽样、对照组和干预组及试验因素的关系厘定、干预有效性的统计学意义和临床意义等方面,总结并梳理了随机对照试验受限情况下如何制定次优策略以保障干预的有效性。研究重点关注了干预的统计学意义和临床意义、两者之间的关系及其在社会工作干预中的价值,这对于我们深入思考在随机对照试验受限的前提下,如何实现社会工作干预的有效性有一定的启发意义,也能够为社会工作干预的开展提供一些参考。社会工作干预的对象往往属于社会弱势群体,干预的指向性明确,经常无法实现大样本的随机抽样,因此干预是否有效结论的得出,不仅需要统计学意义的佐证,更应该通过临床获益程度做出判断。当样本量过大或过小、协变量多等因素导致统计学意义不稳定时,研究者更应该突破仅限于统计学的视野,同时关注更能体现对干预对象有实际改善作用的临床意义。在实际干预中,只有明确具体干预对问题改善所具有的临床意义,才能为最优化的干预方案提供决策依据;在科研方面,明确结局指标变化的具体临床意义,才能为后续研究提供充分的数据支持。因此,临床意义应该与统计学意义一起,共同构成衡量干预有效性的核心标准。
基于“让我们做朋友”干预的分析,应对随机对照试验受限有三个主要策略。第一个策略的基本理念是对于社会工作干预而言,受限的高质量随机对照试验比非随机对照试验更好。因此,可以根据干预的具体情况对未能达到随机对照试验的要求及原因加以说明和报告,并在最大程度上选择次优方案以确保干预效果。具体来看,在干预设计上,针对样本量小的问题,可适度接受统计功效和效应量的折损;针对干预对象异质性强的问题,在统计分析时可以纳入协变量进行控制以减小选择性偏误;针对抽样问题,当无法实现较低误差的抽样方法,可以考虑简单随机抽样和整群抽样。在干预实施上,应优先遵循社会工作伦理原则,在“知情同意”的前提下灵活实施单盲,能够有效排除干预对象的主观偏见和心理变化带来的影响,降低主观偏误,提升干预有效性;通过强化对照意识,尽量建立干预组与对照组的分隔,降低干预效应的溢出。在干预效果评价上,基于多中心比较和历史对照,增强干预结果的说服力;采用多重结果指标同时测量,相互印证。第二个策略是选择使用NRSI次优方案,如前述队列研究、病例—对照研究、时间序列研究,以及目标值试验(OPC)、专家意见(expert opinion)等方法同样具有效力,甚至可以实现比随机对照试验更好的外部有效性。20世纪60年代有学者提出研究证据质量分级思想,随后各个国家权威机构纷纷出具分级标准,表明在随机对照试验要求的条件难以满足的情况下,其他证据分级稍低一些的方法同样可以成为选择。如加拿大预防医学工作组(CTFPHC)和美国预防医学工作组(USPSTF)的临床研究证据质量的分级方法以及证据金字塔被广泛认同和使用。第三个策略是将随机对照试验与次优方案的证据进行整合分析,Cuello-Garcia认为,“整合”一词泛指将RCT与NRSI一起使用的任何形式,可以在证据报告表中分别展示,也可以分别进行Meta分析,甚至可以分别计算两种研究设计的合并结果。从而综合权衡RCT与NRSI的优势与缺陷,做出最有利于证据的选择。当然,其关键点在于预先对复杂过程、复杂方法的把握程度,以及每一个判断节点的谨慎、合理。这一构想是研究者在漫长的循证实践过程中以实际问题为导向反复思索的产物。
总之,干预研究是社会工作领域的前沿热点,强调基于科学的证据来检验实践,对于提升社会工作干预的有效性极具意义,而随机对照试验是干预研究科学证据中的重要一环。如何理解随机对照试验的各个步骤,如何在其指导下提升社会工作干预的可信度,如何在条件受限时探索保证干预有效性的次优策略,如何同时确保临床意义和统计学意义,是循证社会工作需要进一步挖掘和聚焦的方向。
原文责任编辑:李文珍













